東京大学松尾研究所の寄付講座、修了しました!
AIの研究で有名な、東京大学の松尾先生が監督する
機械学習の講座の修了証が届きました!
仕事でユーザーのアクセスログを見る中で、
データ分析によって得られる客観的な事実とパターンの発見が興味深く、活用の幅も大きいと考えて、勉強を2018年の春頃から始めました。
この講座は2018年11月から始まり2019年3月までの約4ヶ月間で、
毎週欠かさずオンライン学習と課題の提出を重ねました。
独学でPyQに取り組んだり本をやったりもしていましたが、
この講座では基本のヌケモレを補完しながら、学習のペースを保てたところが良かったです。
引き続き、ユーザー理解のためのデータ分析を続けていきたいと思います!

ユーザークラスタリング手法を調べたのでまとめてみた
ユーザーのクラスタリングをしようと思い、先行事例をググってまとめました! (※前提として、「ログイン機能のないwebサイトにおける、登録者数増加」を最終目的としています。)
結論
- たくさんある。まずは単純集計して、傾向を掴み、次に以下の切り口を真似するのが良さそう。
ユーザの行動履歴データを用いたコンテンツ興味推移カテゴリの可視化手法
調べたものを羅列
東大松尾さんの、興味ジャンル、興味レベル、興味行動(時系列)で分類した事例
- 切り口:マンガのテーマ、その興味レベル、興味行動をもとに分類
- 方法:それぞれFuzzy C-means 法、Yang氏の論文に記載のスコアリング、評価4以上をつけたかなどの行動指標 で算出し、論文に記載の独自式で計算
- 良い点:テーマ、興味レベル、関心の推移の切り口であるため、応用が効きそう
- 活用イメージ:記事テーマ、購買意欲レベル、購買フェーズに至るまでのプロセス、で応用できそう
- ユーザの行動履歴データを用いたコンテンツ興味推移カテゴリの可視化手法
マンガサービス(LINEマンガ?)のクラスタリング
-
- 切り口:時間帯ごとのアクセス回数の比率を使って、活動時間の特徴別に分類
- 方法:kmeans法
- 良い点:行動パターンと商品内容からどのような人物なのか推定がつく(例:昼間にファッション系のアイテムの売買が多い=主婦層 など)
- 活用イメージ:行動パターンからどういう趣味嗜好があるひとなのかの推測ができるためレコメンドなどができそう
- クラスタ分析を駆使して、メルカリのユーザのことをもっとよく知ろう! | mercan (メルカン)
サイバーの広告におけるセグメント分け
- 切り口:接触広告媒体、購入商品、CV種類?
- 方法:階層型クラスタリング
- 良い点:どの広告媒体にどれくらい接触している人が、どういう商品を買っているのかがわかるので、即決ユーザーか、優柔不断ユーザーかなどがわかる
- 活用イメージ:CVしたユーザーのうち、どういうテーマを見ている人がどういう属性だったのか
- ユーザー行動を階層型クラスター分析で分けてみた。 | インターネット広告代理店で働くデータサイエンティストのブログ
行動ログ以外のデータを活用しているもの
-
- 切り口:都道府県ごとの、応募者数×属性(フリーター、学生)
- 方法:階層型クラスタリング
- 良い点:どの都道府県にどの属性が多くて、それらがどれくらい応募しているのかわかり、類似県をまとめられる
- 活用イメージ:閲覧ページのテーマ×応募数×応募属性で分類し、どのテーマがどの属性向けのコンテンツなのかわかる。
- ユーザー属性を利用した都道府県のクラスタリング-LIVESENSE DIGITAL MARKETING
エンジニア分類
- 切り口:使用言語の種類
- 方法:非階層型クラスタリング、特異値分解によって次元削除している
- 良い点:どの言語を使っている人がどの言語も使っているという傾向がみれる
- 活用イメージ:記事分類。 特異値分解によって、相関が強い変数を削除できるなどしそう。
- https://qiita.com/sergeant-wizard/items/ef62680d2b7d458eb256
ヴァリューズの分析
- 切り口:購買傾向アンケートをもとに
- 方法:非階層型クラスタリング、特異値分解によって次元削除している
- 良い点:どの言語を使っている人がどの言語も使っているという傾向がみれる
- 活用イメージ:記事分類。 特異値分解によって、相関が強い変数を削除できるなどしそう。
- https://qiita.com/sergeant-wizard/items/ef62680d2b7d458eb256
注意点や手法など
注意点
- セグメントの目的を明らかに
- 良いセグメントの条件
- MECE
- ボリュームが偏っても欽一でも構わないが特徴がある状態を目指す
- 大雑把すぎず、細かすぎない。3-7つくらいが妥当らしい
おおまかな分析手順
- やり方例
- 基本属性でで単純集計する (性別など)
- 集計結果をさらに分ける(売上金額、利用状況など)
- 説明したい事象に対して、データの意味付けを行い分類する(新規、リピート、リターン)
クラスタリングの切り口
- 人口動態変数:CVしていないと不明
- 地理的変数:学校からのアクセス?会社からのアクセス?
- 行動変数:就職動機、閲覧回数、閲覧時間、購買フェーズ
- 心理的変数:ライフスタイル、悩みの内容?

https://www.slideshare.net/naototamiya9/ss-76662203
クラスタリングの分析手法をざっと
-
- その指標にける割合を、単純にABCランクに分ける
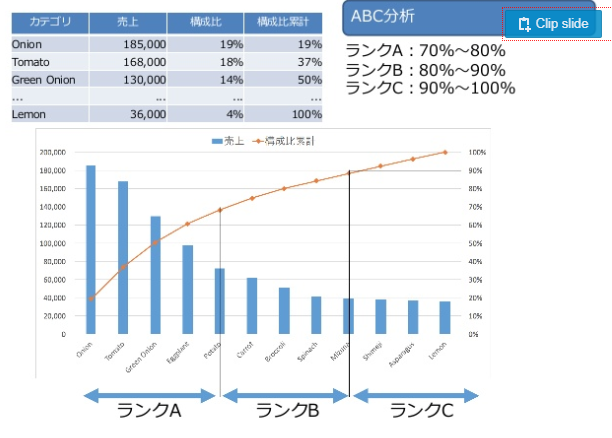
https://www.slideshare.net/naototamiya9/ss-76662203
- その指標にける割合を、単純にABCランクに分ける
- デシル分析
- ユーザーを10段階に分ける
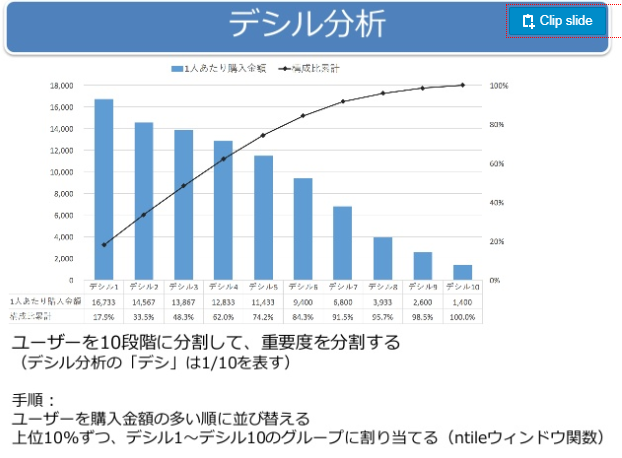
https://www.slideshare.net/naototamiya9/ss-76662203
- ユーザーを10段階に分ける
REM分析
- Recency、Frequency、Monetaryに分ける
- ECやログインしていないサービスだと難しいかも。やるとすると、登録後の動きか、アクセス日、購入フェーズ≒購入金額(スコアリングする)、リピート数など。△

https://www.slideshare.net/naototamiya9/ss-76662203 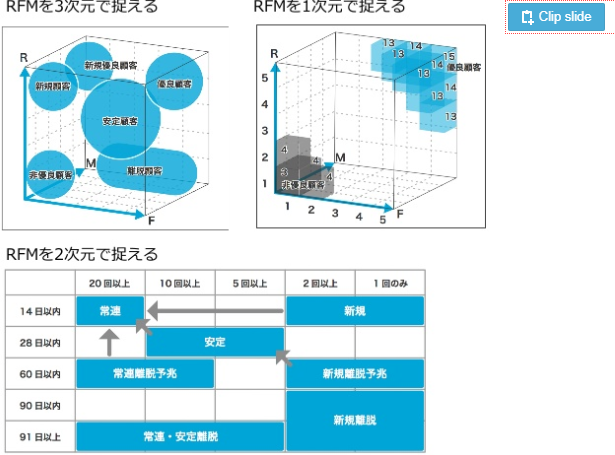
階層クラスタリング活用例:CVしたユーザーとしてないユーザーでクラスタリングを行い、その要因から導線設計などを行う(つまり活用にするには、一度属性などでクラスタリングを行い、その中でCVしたユーザーとそうでないユーザーの2分類に分けて、行動をクラスタリング(ページ数、時間など)して要因を特定するなどがありそう)
- 非階層クラスタリング活用例:ユーザー行動ログからにたユーザーを分類し、その行動パターンからレコメンドを行う
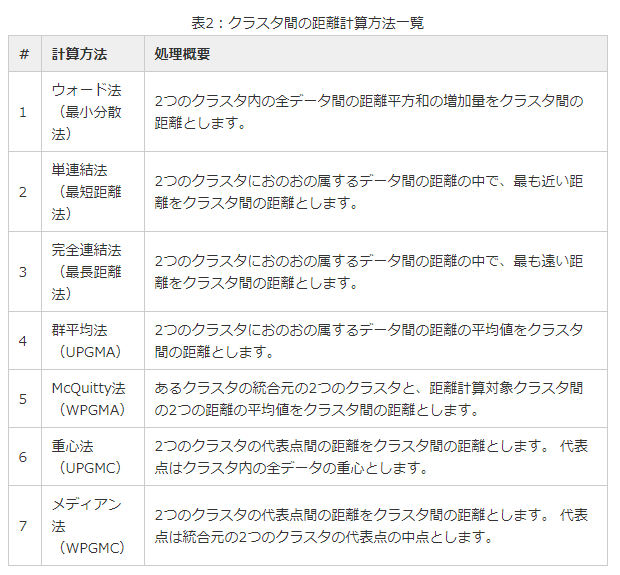
https://enterprisezine.jp/iti/detail/6762?p=2 - 主成分分析:多くの変数を持つデータ・セットから特徴を表す新たな合成変数を作成する手法、それにより説明変数の圧縮を行う
- ソフトクラスタリング:TOPIC分類のように、複数のクラスタに所属しそれぞれの確率を算出する
SQL presto 時間型の変更まとめ
型の種類
timestamp unixtime varchar date
型変換
- bigint型のunixtime→人間にとって見やいvarchar型にする
TD_TIME_FORMAT(x,'yyyy-MM-dd','JST') TD_TIME_FORMAT(1420038000 ,'yyyy-MM-dd','JST') -> 2015-01-01
[in] 1420093526 bigint(unixtime) [out] '2018-10-29' varchar
- 人間にとって見やすいvarchar型 → bihing型のunixtime
TD_TIME_PARSE('2015-01-01','JST') -> 1420038000
- bigint型のunixtime→ timestamp型
FROM_UNIXTIME(time) FROM_UNIXTIME(1420093526 ) -> 2018-09-10 00:00:00.000
[in] 1420093526 bigint (unixtime) [out] 2018-09-10 00:00:00.000 (timestamp)
その他便利な関数
- timestamp型などを引数にもって、指定した単位で切り上げる
DATE_TRUNC(unit.x) DATE_TRUNC('month', 2018-09-15 00:00:00.000 ) -> 2018-09-01 00:00:00.000
※xにはtimestamp型などが入る
SQL presto bigint型のunixtimeから年月を取り出す方法
やりたいこと
time = 1519822868 [bigint型のunixtime] から年月を取りだしたい
方法
date_trunc('week',FROM_UNIXTIME(time))
解説
- bigint型のunixtime→ timestamp型
FROM_UNIXTIME(time)
- 年月だけ抜くには「月」で切り上げる
date_trunc('month', x)
※x = timestamp型などが入る
参考
6.13. Date and Time Functions and Operators — Presto 0.213 Documentation
記事の自動タグ付け方法について
記事の自動タグ付けがしたくて、事例を調べてみました!
つまりどれが良さそう?
- 1記事1タグなら:記事分類→分類ごとに出現頻度の高い単語をタグ付け
- 1記事nタグなら:本当は事例4のやり方が良さそう。ただBM25の使い方が理解できていない・・
簡単にいうと?
- 事例1:記事を先に分類し、その中から出現頻度の高い単語をタグとして採用する
- 事例2:記事ごとに、上位200文字の中からTF-IDFで重要単語として上がったものを5つ設定
- 事例3:記事ごとに、特徴単語をBM25で抽出してタグ付け
- 事例4:記事ごとに、独自ロジック(TF=IDF、BM25活用)で特徴単語を抽出しタグとして適用
具体的には?
事例1 ~記事を先に分類し、その中から出現頻度の高い単語をタグとして採用する~
- 出現頻度の高いキーワードの中から上位 5 つを関連タグとして付与する http://www.anlp.jp/proceedings/annual_meeting/2012/pdf_dir/F2-5.pdf
分析手順
- カテゴリ別に収集した記事群においてコサイン類似度を用いて記事の類似度を測定する.
- 類似度が高く関連性が高い記事を収集する.
- 記事群の中でクラスタを生成する.
- クラスタ内において頻出単語 (関連タグ) を抽出する.
- 頻出単語 (関連タグ) をクラスタを構成する記事に対して付与する

事例2 ~記事上位200文字の中からTF-IDFで重要単語として上がったものを5つ設定~
- 抽出したキーワードについて,TF-IDF 値を求め,得られた重要タグにタイトルタグとカテゴリタグを追加
加えて、何人かにタグを付けてもらいそれを正解データとして以下の場合でタグ付けした時の正答率を求めている
方法 1:キーワード抽出箇所全文,タグ数 5 つとした場合.→正答率低
- 方法 2:キーワード抽出箇所 200 文字目まで,タグ数 5 つとした場合.→正答率高
- 方法 3:キーワード抽出箇所全文,文字数によってタグ数を変化させる場合.→正答率中(記事によっては多くのタグをつけることができ説でない場合がある)
https://www.jstage.jst.go.jp/article/fss/26/0/26_0_21/_pdf/-char/ja
分析手順
- 記事情報の取得
- 形態素解析
- TF-IDF 計算
- タグ付け
- 古い記事の削除
- タグの重要度更新
事例3 ~記事ごとに特徴単語をBM25で抽出してタグ付け~
- Okapi BM25 の操作を自作して自動タグ付け(※結果精度は粗いらしい)
事例4 ~記事ごとに独自ロジック(TF=IDF、BM25活用)で特徴単語を抽出しタグとして適用~
特徴
- BM25で分類、かつ、一般語を更に弾くために青空文庫のデータを一般辞書としてtf-idfのロジックに組み込む
- それらのデータを元にタグ付け